字节终面:说说看B树和B+树的理解和区别?在B+树中,如何通过减少磁盘I/O操作来提高查找效率?
原创 程序员阿沛 程序员阿沛 [ 程序员阿沛 ](javascript:void(0);)
本文归于合集: 吊打面试官系列
面试题概览:
-
说说看B树和B+树的理解和区别?
-
B树是如何保持其平衡性的?请描述B树在插入和删除操作后如何调整结构以保持平衡。
-
在B+树中,如何通过减少磁盘I/O操作来提高查找效率?
-
在B+树中,所有实际的数据记录都存放在哪里?索引节点存放的是什么?
** 面试官:请说说看B树和B+树的特点和结构是怎样的? **
B树(B-Tree)和B+树是两种重要的数据结构,它们在数据库和文件系统中有着广泛的应用。以下是对B树和B+树的详细理解:
B树
- 定义与特点 :
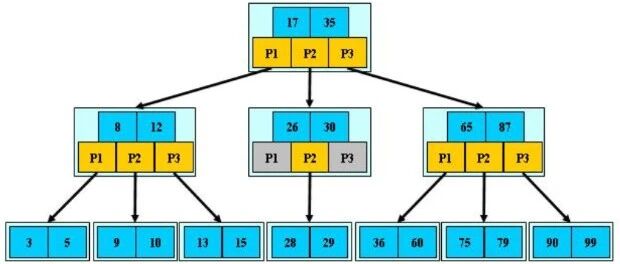
* B树是一种自平衡的树状数据结构,专为磁盘和其他直接访问的辅助存储设备而设计。
* B树通过保持树的平衡性,确保所有叶子节点都在同一层,从而实现了高效的查找、插入和删除操作。
* B树的每个节点可以拥有多个子节点和键值,且节点中的键值按照升序排列。
* 
*
- 结构与操作 :
* B树的阶(Order)或分支因子(Branch Factor)通常用字母m表示,它定义了节点可以拥有的最大子节点数(即m个子节点)。因此,一个节点最多可以有m-1个键值。
* 非根节点至少需要有⌈m/2⌉个子节点,以保持树的平衡。
* 搜索操作从根节点开始,通过比较要查找的键与节点中的键,决定是继续在左子树还是右子树中搜索。
* 插入操作首先找到合适的叶子节点,然后将新键插入该节点。如果插入后节点中的键的数量超过了m-1,则节点会分裂成两个节点,并将中间的键提升到父节点。
* 删除操作首先找到包含要删除键的节点,并从节点中移除该键。如果删除后节点中的键的数量少于要求的最小数量(⌈m/2⌉-1),则需要重新分配或合并节点。
*
B+树
- 定义与特点 :
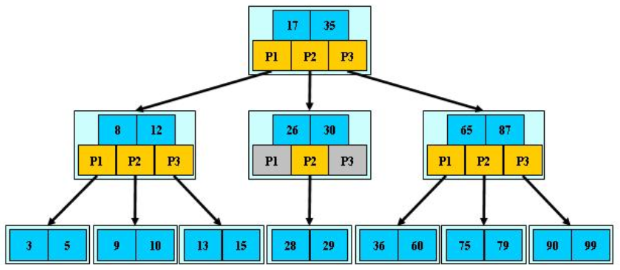
* B+树是B树的一种变种,它在B树的基础上做了一些改进。
* B+树的所有键值都存储在叶子节点中,并且叶子节点之间通过指针相连,形成一个有序链表。
* 这种结构使得B+树在范围查询和顺序访问时更加高效。
* 
- 结构与操作 :
* B+树包含两种类型的节点:索引节点(内部节点)和叶子节点。索引节点只包含键,不包含数据,而叶子节点则存储键和对应的数据。
* 索引节点的键是升序排列的,对于指定的索引节点键来说,它左子树上所有的键都小于它的键,它右子树上所有的键都大于等于它的键。
* 所有叶子节点都在同一高度上,且节点按键从小到大排列,并通过指针彼此链接,形成一个双向有序链表。
* B+树的插入和删除操作与B树类似,但需要考虑叶子节点和索引节点的分裂与合并。
* 由于B+树的所有数据都存储在叶子节点中,且叶子节点之间通过指针相连,因此在进行范围查询和顺序访问时,可以高效地遍历叶子节点,而无需访问索引节点。
*
B树和B+树都是自平衡的树状数据结构,它们通过保持树的平衡性来实现高效的查找、插入和删除操作。B树适用于需要频繁进行插入、删除和查找操作的场景,而B+树则更适合于范围查询和顺序访问的场景。在实际应用中,B树和B+树都被广泛应用于数据库和文件系统中,以提高数据存取的效率。
** 面试官:再说说看它们的区别是什么,应用场景是什么? **
B树和B+树它们之间有几个关键的区别,具体如下:
一、节点存储数据的方式
-
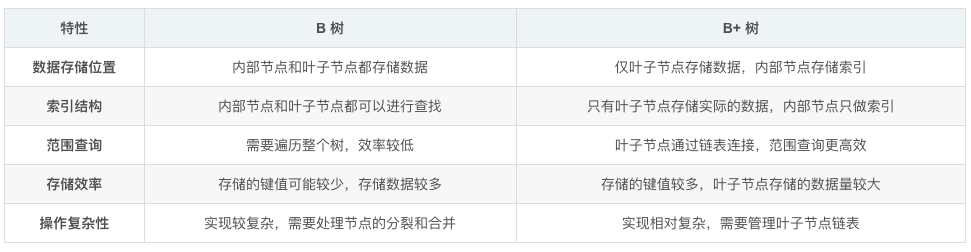
B树 :非叶子节点和叶子节点都会存储数据,即指针和数据共同保存在同一节点中。具体来说,B树的每个节点可以拥有多个子节点和多个键值,这些键值在节点中按照升序排列,并且节点中的键值数量在一定范围内(通常是[⌈m/2⌉, m-1],其中m是B树的阶或最大度数)。
-
B+树 :数据只保存在叶子节点,非叶子节点只存储索引信息(即键值),不存储实际的数据记录。这种结构使得B+树在查找过程中,非叶子节点仅用于索引定位,而实际的数据访问发生在叶子节点。
二、查找数据的过程
-
B树 :由于B树的非叶子节点也存储数据,因此查找过程可能在这些节点上进行,查找效率不稳定。每次查找可能需要访问更多个或更多层节点,才能找到目标键值或确定目标键值不存在。
-
B+树 :查找过程仅在叶子节点上进行,非叶子节点仅用于索引定位。
三、空间利用率
-
B树 :由于每个节点都存储数据,空间利用率相对较低。特别是在存储大量数据时,B树的节点可能会变得非常庞大,导致内存或磁盘空间的浪费。
-
B+树 :只有叶子节点存储数据,非叶子节点仅存储索引信息。这种结构使得B+树在相同数据量下,能够更有效地利用空间。因为非叶子节点只存储索引,所以它们可以包含更多的键值,从而指向更多的子节点,降低树的高度。
四、结构稳定性
-
B树 :插入和删除数据需要频繁变更树的结构,包括节点的分裂和合并等操作。这些操作可能会破坏树的平衡性,导致查找效率下降。
-
B+树 :插入和删除数据操作主要集中在叶子节点上,非叶子节点仅用于索引定位。这种结构使得B+树在插入和删除数据时能够保持较好的结构稳定性,减少了对树结构的频繁变更。
五、范围查找性能
-
B树 :范围查找需要在各个节点上逐个查找,效率相对较低。
-
B+树 :由于叶子节点之间通过指针相连形成链表,且所有数据记录都存储在叶子节点上,B+树在进行范围查找时只需沿着链表上遍历即可。这种结构使得B+树在范围查找方面具有更高的效率。
综上所述,B树和B+树在节点存储数据的方式、查找数据的过程、空间利用率、结构稳定性和范围查找性能等方面存在显著差异。在实际应用中,B+树因其更高的空间利用率和更好的查询性能而更适合用作大型数据库的索引结构。
六、应用场景
B 树
文件系统:B 树适用于需要频繁插入、删除操作的场景,如文件系统的目录结构。
数据库索引:适合需要频繁更新的索引结构。
B+ 树:
数据库索引:由于提供了高效的范围查询,B+ 树广泛用于数据库索引中,尤其是对范围查询性能有高要求的场景。
大规模数据存储:适用于需要高效范围查询和数据存储的场景,如数据仓库和日志系统。
** 面试官:B树是如何保持其平衡性的?请描述B树在插入和删除操作后如何调整结构以保持平衡。 **
B树是一种自平衡的树数据结构,它能够在插入和删除操作后自动调整以保持平衡,从而保证查找、插入和删除操作的效率。B树保持其平衡性的关键在于其独特的节点分裂和合并机制,以及插入和删除操作中的调整策略。
插入操作后的平衡性维护
当向B树中插入新键值导致节点键值数量超过上限(m-1,其中m是B树的阶或最大度数)时,节点会分裂成两个节点,并将中间键值上移到父节点。这个过程可能会一直向上传播到根节点,如果根节点分裂,则树的高度会增加。插入操作中的平衡性维护具体步骤如下:
-
找到插入位置 :从根节点开始,根据键值的大小向下遍历树,直到找到一个叶子节点或内部节点,该节点包含的关键字数量小于m-1。
-
插入新键值 :如果找到的是叶子节点,将新键值插入到正确的位置,并调整节点的键值数量。如果找到的是内部节点,将新键值插入到正确的子节点中。
-
节点分裂 :如果插入新键值后,节点键值数量达到m(即节点满),则进行分裂操作。创建一个新的节点,将原节点中一半的关键字(以及相应的子节点指针)移动到新节点中。将原节点中的第一个关键字(在分裂后剩余的关键字中)提升到父节点中,成为两个子节点的分隔关键字。
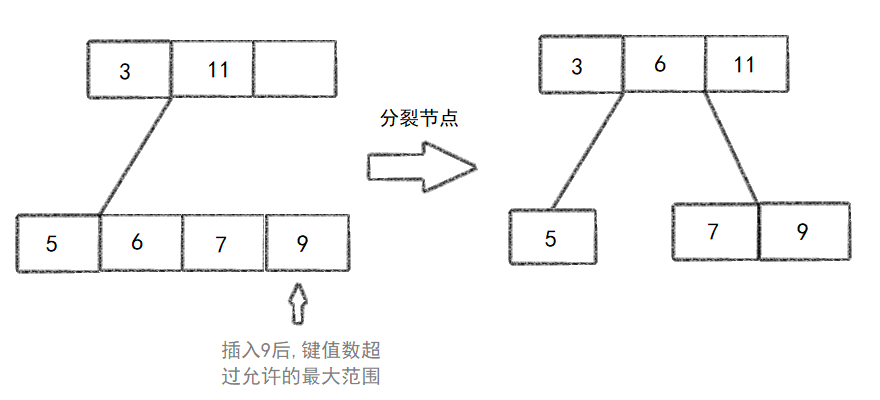
- 递归调整 :如果分裂操作导致父节点也满,则递归地进行分裂和调整,直到根节点或找到一个不满的父节点为止。
删除操作后的平衡性维护
从B树中删除键值可能涉及更复杂的情况,因为需要保持节点的键值数量在允许的范围内(即⌈m/2⌉-1到m-1之间)。删除操作通常从包含键值的叶子节点开始。如果删除后节点的键值数量低于下限(⌈m/2⌉-1),则可能需要从相邻的兄弟节点中借调键值(如果可能的话),或者与相邻的兄弟节点合并,并将父节点中的相应键值下移。这个过程可能也会向上传播。删除操作中的平衡性维护具体步骤如下:
-
找到删除位置 :从根节点开始,根据键值的大小向下遍历树,直到找到包含要删除键值的叶子节点。
-
删除键值 :从叶子节点中删除指定的键值,并调整节点的键值数量。
-
节点合并或借调键值 :如果删除键值后,节点键值数量低于下限(⌈m/2⌉-1),则进行以下操作之一:
* 借调键值 :如果相邻的兄弟节点有多余的键值,可以从兄弟节点中借调一个键值来保持平衡。这通常涉及父节点中分隔键值的调整。
* 节点合并 :如果相邻的兄弟节点没有多余的键值,则需要与相邻的兄弟节点合并。合并后,将父节点中的相应分隔键值下移到合并后的节点中(如果合并发生在根节点,则可能导致树的高度减少)。
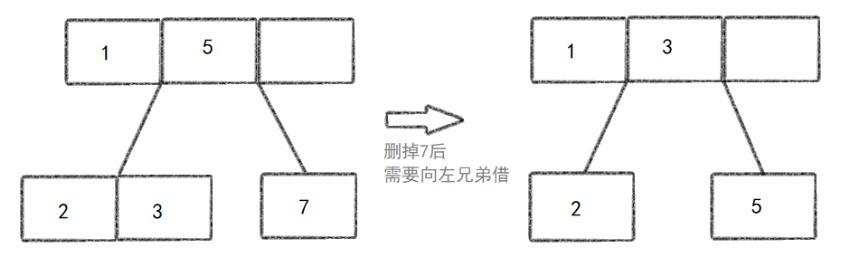
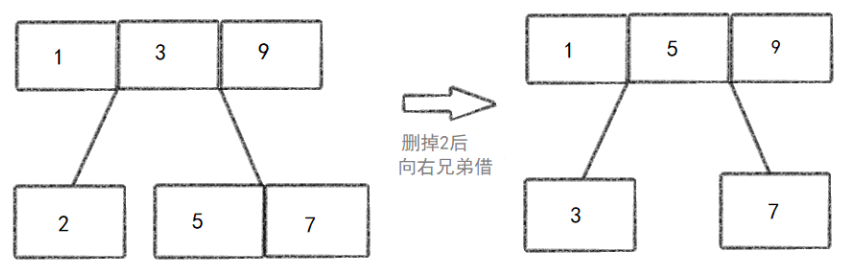
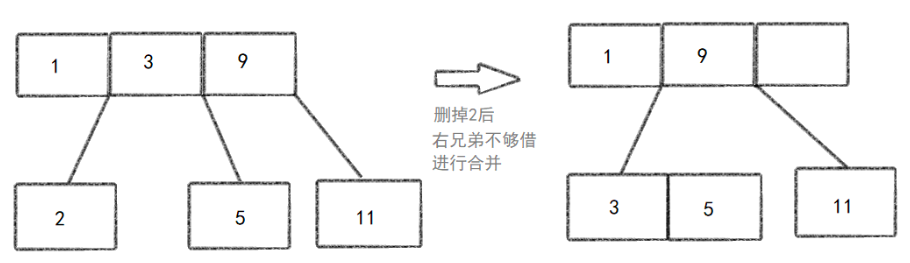
- 递归调整 :如果合并或借调键值操作导致父节点也低于下限,则递归地进行调整,直到找到一个平衡的父节点或根节点为止。
以下代码是用Python编写的B树自平衡实现,为了简化,我假设B树的阶(即最大度数)为3(即每个节点最多可以有2个键和3个子节点)。
class BTreeNode: def __init__(self, leaf=False): self.leaf = leaf self.keys = [] self.children = []
class BTree: def __init__(self, t): self.root = BTreeNode(leaf=True) self.t = t # Minimum degree (defines the range for number of keys)
def traverse(self, node): # Inorder traversal of the B-Tree i = 0 while i < len(node.keys): if not node.leaf: self.traverse(node.children[i]) print(node.keys[i], end=' ') i += 1 if not node.leaf: self.traverse(node.children[i])
def search(self, k, x=None): # x is current node, default is root if x is None: x = self.root i = 0 while i < len(x.keys) and k > x.keys[i]: i += 1 if i < len(x.keys) and k == x.keys[i]: return x if x.leaf: return None return self.search(k, x.children[i])
def insert_non_full(self, k, y): # Insert key k into node y i = len(y.keys) - 1 if y.leaf: y.keys.append(None) while i >= 0 and k < y.keys[i]: y.keys[i + 1] = y.keys[i] i -= 1 y.keys[i + 1] = k else: while i >= 0 and k < y.keys[i]: i -= 1 i += 1 if len(y.children[i].keys) == 2 * self.t - 1: self.split_child(y, i) if k > y.keys[i]: i += 1 self.insert_non_full(k, y.children[i])
def split_child(self, y, i): # Split child y.children[i] and insert into y z = y.children[i] y.children.insert(i + 1, BTreeNode(leaf=z.leaf)) y.keys.insert(i, z.keys[self.t - 1]) z.keys = z.keys[:self.t - 1] if not z.leaf: y.children[i + 1].children = z.children[self.t:(2 * self.t - 1)] z.children = z.children[:self.t - 1]
def insert(self, k): # Insert key k into the B-Tree root = self.root if len(root.keys) == 2 * self.t - 1: temp = BTreeNode() self.root = temp temp.children.insert(0, root) self.split_child(temp, 0) self.insert_non_full(k, temp) else: self.insert_non_full(k, root)
# Example usage: t = 2 # Minimum degree btree = BTree(t) keys = [10, 20, 5, 6, 12, 30, 7, 17]
for key in keys: btree.insert(key)
print("Inorder traversal of the constructed tree is:") btree.traverse(btree.root)
**
**
**
**
** 面试官:在B+树中,如何通过减少磁盘I/O操作来提高查找效率? **
以下是B+树通过减少磁盘I/O操作来提高查找效率的具体方式:
一、节点存储优化
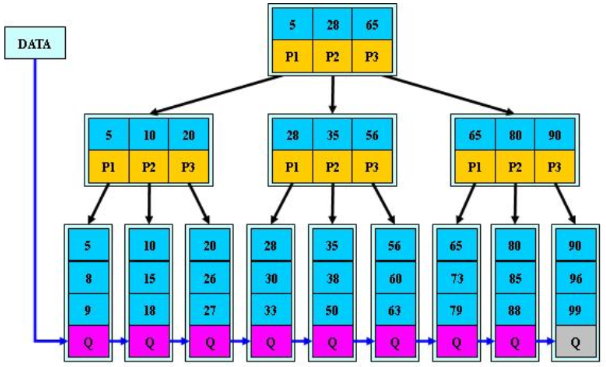
- 非叶子节点仅存储键值 :
* B+树的非叶子节点只存储键值信息,而不存储实际的数据记录。这样做的好处是每个节点能够存储更多的键值信息,从而使得查询同一层次的所有数据时,能够一次性读入更多的数据块。
- 叶子节点存储全部数据 :
* 所有实际的数据记录都存储在B+树的叶子节点中,并且叶子节点之间通过指针相互连接,形成一个有序链表。这种结构使得数据的存储更加集中,便于快速访问。
*
二、磁盘预读特性利用
- 节点大小与磁盘块匹配 :
* B+树的设计考虑到了磁盘存储的特性,通常将节点的大小设置为与磁盘块的大小相匹配。这样做可以减少磁盘寻址次数,因为每次磁盘I/O操作可以读取一个完整的节点。
- 顺序访问优化 :
* 由于B+树的叶子节点通过指针连接成有序链表,当进行范围查询或顺序访问时,可以快速地遍历所有叶子节点,而无需频繁地进行磁盘I/O操作。
*
三、树形结构优化
- 保持树的平衡 :
* B+树是一种自平衡的树形数据结构,所有叶子节点都在同一层级上。这种平衡性保证了每次查找的路径长度相同,从而提供了稳定的查询性能。
- 减少树的高度 :
* 由于非叶子节点可以存储更多的键值,B+树的高度通常比B树更低。较低的高度意味着较少的磁盘I/O操作次数,因为每次查找都需要从根节点开始逐层向下遍历。
*
四、范围查询和区间扫描
- 高效的范围查询 :
* B+树特别适合于执行范围查询和区间扫描。由于叶子节点之间通过指针连接成有序链表,可以快速地定位到查询范围的起始节点,并顺序遍历所有符合条件的节点。
- 减少不必要的磁盘访问 :
* 在进行范围查询时,B+树可以避免访问非叶子节点,因为所有实际的数据都存储在叶子节点中。这样可以减少不必要的磁盘I/O操作,提高查询效率。
综上所述,B+树通过优化节点存储、利用磁盘预读特性、保持树的平衡以及支持高效的范围查询等方式,显著减少了磁盘I/O操作次数,从而提高了查找效率。
**
**
欢迎在评论区留言表达看法 或 提出你想学习的技术内容 与 面试问题,阿沛会一一作出回复。
如果本文对大家有帮助,麻烦大家动动小手点个免费的“赞”或“在看”,大家的鼓励就是阿沛持续更新的动力~

** -- 往期精彩 – **
面试题:说说看进程、线程和协程的区别是什么?协程能够并行吗?Goroutine和Coroutine的区别是什么?
途虎一面:为啥要有传输层?传输层除了可靠性还有什么特性?数据帧被截断如何保证可靠性?IP包丢失了怎么办?
计算机网络基础(七) 传输层之TCP滑动窗口、流量控制、拥塞控制、连接管理和TCP中的计时器
操作系统入门(十) 文件系统篇之文件与目录的逻辑结构、文件索引节点
**
**